Megan R. Brett is a digital public historian and a scholar of the early United States. She a Ph.D. in History from George Mason University. From 2014 through 2022 she was a Digital History Associate at RRCHNM.
We have talked on the blog about some of the datasets we are transcribing from the Bills of Mortality - the counts of death by parish, causes of death, and christening and burial numbers. Some of the bills have even more information on them: the price of bread (and eventually other foodstuffs). But why would state-mandated bread prices be included in the Bills of Mortality? To find out, we need to look more closely at the role of bread in early modern England.
Once items are added to DataScribe and the datasets are ready for transcription, the transcription workflow begins. The project owner can assign users one of two roles: reviewer or transcriber. Reviewers can edit all records and items, regardless of the item’s status. For Bills of Mortality, Reviewers include the staff members on the project and our Digital History Research Assistants. Transcribers can only edit records and items which are locked to them. The Bills of Mortality transcription team is made up of undergraduate and graduate students.
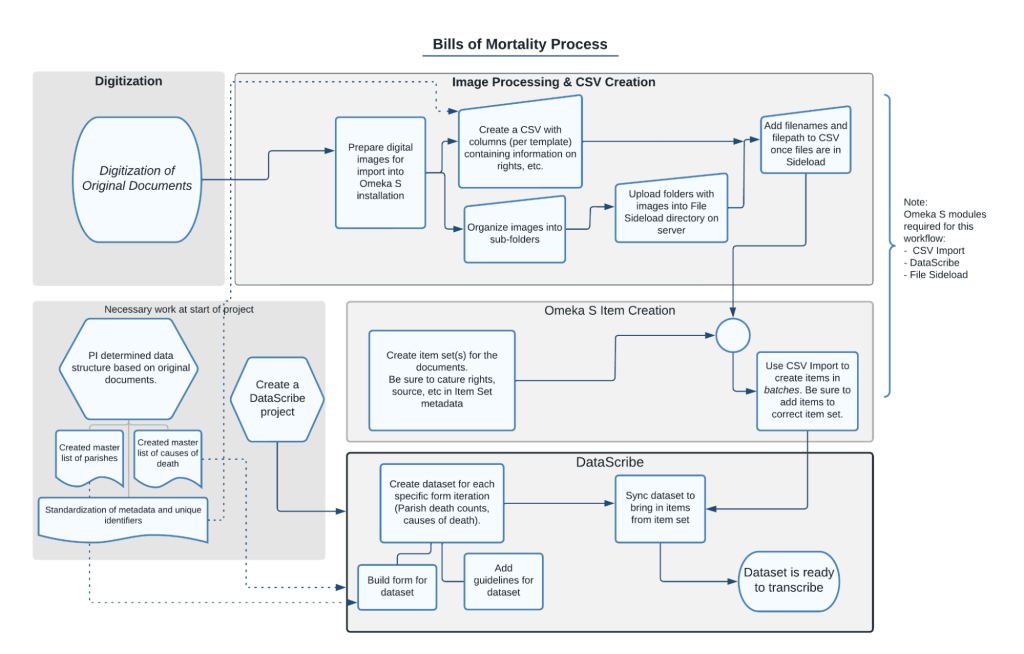
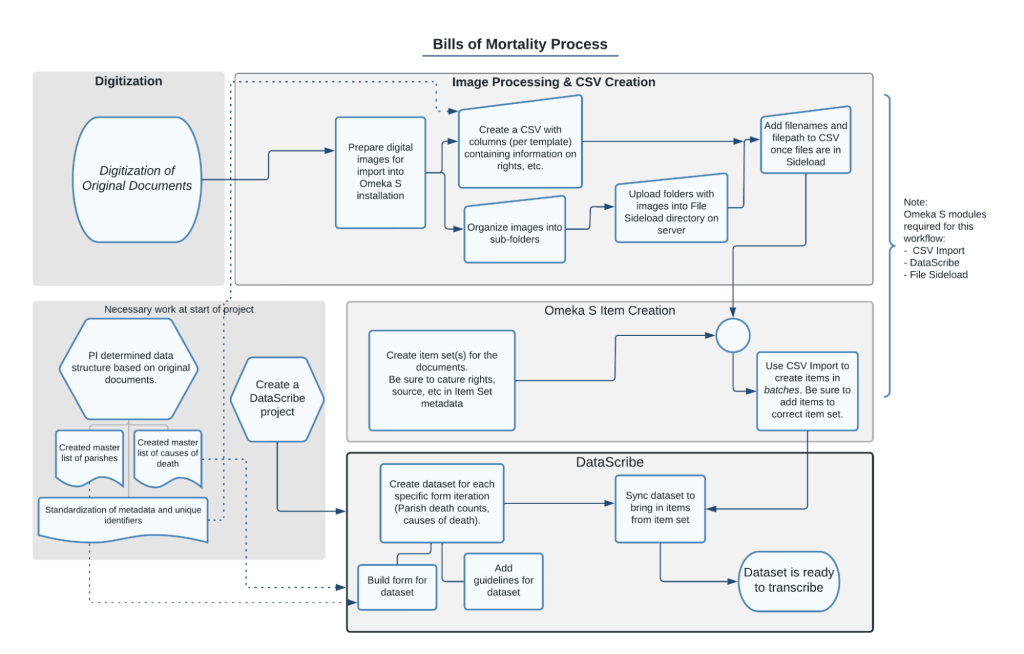
In our last post, we explained how we used Tropy to organize photographs of bound bills into items, concluding with the export of the item metadata using the Tropy CSV Export plugin. This post covers the other part of the process of going from digital images to items in a datascribe item set. If you look at the workflow image, we’ll be describing work that takes place in the “Image Processing and CSV Creation” and “Omeka S Item Creation” areas.
Have you ever wondered how a complex project like Death by Numbers comes together? This post is the first in a series about the workflow that takes us from archival sources to transcriptions formatted for computational analysis. Let’s begin with digitization.
Figure 1. diagram of image preparation workflow showing process from digitization to image processing and CSV creation to omeka s item creation to datascribe transcription.
The Bill of Mortality from Christmas week in 1664 reports that three people died in the parish of St Foster. But fifty years later, there were happily no Christmas deaths in the parish of St Vedast—or rather, the parish of “St Vedast alias Foster.” Because the parish of St Vedast is the parish of St Foster. Welcome to the complex world of early modern parish names.
Given that our sources were published over the course of centuries, it’s hardly surprising that the names of some of the parishes in the bills changed over time. It does, however, present a bit of a challenge for our project since transcribers must be able to match the names in the bills to the names on the transcription form. And even if we were to change the names on the transcription form to accommodate changing parish names, analyzing bills of mortality over time still requires us to know whether a parish listed on a bill in 1582 is the same as a parish listed in a bill in 1752. Our solution has been to create a master list of the parish names, which includes the parish names we use on the transcription forms along with variant names that transcribers might encounter over time. These variant names are then included both in the transcription form and the detailed guidelines for our transcribers.